In large service networks, managing wait time is one of the most difficult operational challenges. Customers expect clear estimates and consistent service, but demand often changes by hour, location, and service type. When wait times vary widely or feel unpredictable, frustration increases and staff face constant pressure to explain delays.
Engineering predictable wait times does not mean eliminating queues. It means designing systems that measure demand, balance capacity, and provide accurate wait time estimates across service networks.
This requires structured queue management, standardized service processes, and real-time visibility into operations. When wait times are measured and controlled properly, service networks become more stable, efficient, and easier to manage at scale.
This article explains how large service networks can design processes that make wait times measurable, controllable, and predictable.
The Core Drivers of Wait Time Variability
Wait times in service networks fluctuate because demand and capacity rarely stay balanced. Understanding the main drivers of variation is the first step toward stabilizing wait time performance.
-
Demand Fluctuations
Wait time variability often begins with inconsistent demand. Peak hours, seasonal surges, and marketing campaigns can rapidly increase visitor volume across service networks.
An imbalance between walk-ins and scheduled appointments further disrupts wait times, especially when unplanned arrivals exceed available staff capacity.
-
Staffing Imbalances
Wait times increase when staffing levels do not match demand. Understaffed service counters during peak periods create immediate backlogs across service networks.
Skill mismatches and uneven workload distribution also affect wait time stability. If complex cases are assigned without proper routing, some staff become overloaded while others remain underutilized.
-
Process Inefficiencies
Inefficient service processes directly extend wait times. Manual check-ins slow intake and increase errors, especially in high-volume service networks.
Poor queue prioritization and the absence of triage rules allow simple and complex cases to mix without structure, causing avoidable delays and inconsistent wait time outcomes.
-
Lack of Real-Time Visibility
Without centralized oversight, wait times become difficult to manage. Leadership cannot see where congestion is building across service networks.
Delayed responses to crowding or service slowdowns allow small disruptions to grow into prolonged wait time spikes that affect overall performance.
You might also like - 5 Reasons Why Your Customers Leave Your Business
How to Engineer Predictable Wait Times
Predictable wait times require structured measurement, operational discipline, and continuous adjustment. The following steps explain how service networks can reduce variability and stabilize performance.
Step 1 – Measure Everything That Impacts Wait Time
You cannot control wait time without accurate data. Large service networks must first identify every variable that influences how long customers wait, then measure those variables consistently across locations.
Start by collecting baseline operational data:
Track arrival rates by hour, day, and season to understand demand patterns.
Measure average service duration by service type, not just overall averages.
Record abandonment rates to identify when wait times become unacceptable.
Separate appointment and walk-in data to detect imbalances.
Next, define service-level benchmarks. For example, set a target such as “80% of visitors served within 15 minutes.” Make this measurable and visible.
Finally, standardize how this data is recorded across all service networks. Use one consistent method and reporting structure so comparisons are accurate. Without standardized measurement, wait time analysis will be unreliable and unpredictable.
Step 2 – Standardize Service Workflows
Wait time becomes unpredictable when each location handles the same service differently. Standardizing service workflows reduces variation and makes outcomes more consistent across service networks.
Begin by mapping the full service process from arrival to completion. Document each step clearly, including intake, verification, service delivery, and exit. Remove unnecessary steps and define a consistent sequence that every location must follow.
To implement this effectively:
Create a written standard operating procedure for each service type.
Define maximum acceptable handling time for common transactions.
Align check-in methods so data collection is consistent everywhere.
Eliminate informal workarounds that extend service duration.
When service workflows are uniform, service networks can forecast wait time more accurately because process duration becomes stable and measurable.
Step 3 – Implement Real-Time Queue Visibility
Wait time cannot be controlled if it cannot be seen. Real-time visibility allows service networks to monitor demand and response capacity as it happens, rather than reacting after delays grow.
Implement centralized dashboards that display live wait times, queue length, service duration, and staff activity across all branches. Leadership should be able to compare locations in one view and identify congestion immediately.
To strengthen visibility:
Display live wait times on waiting room TVs so visitors understand queue movement.
Provide managers with real-time alerts when wait times exceed defined thresholds.
Monitor abandonment rates alongside wait times to detect silent service failure.
Use historical comparisons to see whether current performance aligns with targets.

Real-time visibility reduces guesswork and allows service networks to stabilize wait times before service levels decline.
Also read - Dashboard Features You Didn’t Know Could Transform Multi-Department Workflows
Step 4 – Forecast Demand Using Historical Data
Predictable wait times require forward planning, not reactive staffing. Historical data reveals patterns that repeat across service networks and allows managers to prepare before congestion builds.
Start by analyzing arrival data by day of the week, time of day, and season. Look for recurring spikes tied to payroll cycles, benefit renewals, promotional campaigns, or regulatory deadlines. Identify which locations experience consistent demand volatility and which remain stable.
To apply this effectively:
Compare arrival rates and service duration across similar time periods.
Identify peak congestion windows that regularly increase wait times.
Use service intelligence tools to convert historical patterns into demand forecasts.
Adjust staffing schedules and counter allocation based on predicted volume.
When service networks use service intelligence to anticipate demand, wait times become manageable instead of unpredictable.
Step 5 – Align Staffing with Predicted Demand
You must match staffing levels directly to forecasted demand to control wait times. When service networks rely on fixed schedules, they create predictable overload during peak hours and waste capacity during slower periods. Active workforce planning keeps wait times stable and service flow consistent.
To implement this effectively:
Use historical arrival data to build dynamic schedules that increase coverage during peak windows.
Assign staff based on required skills and service complexity to prevent uneven workload distribution.
Add flexible shifts or on-call coverage during known high-demand periods.
Review actual wait times each week and adjust staffing plans based on measurable gaps.
When you actively align staffing with demand, you reduce variability and protect service performance across the network.
Step 6 – Segment and Prioritize Intelligently
You must control how different visitor groups enter and move through service networks to stabilize wait times. When appointments, walk-ins, urgent cases, and complex services all compete in one line, variability increases and delays spread quickly. Clear segmentation protects throughput and keeps wait times predictable.
To implement this effectively:
Separate appointment queues from walk-in queues so scheduled visitors are not delayed by unpredictable foot traffic.
Define written priority criteria for urgent, vulnerable, or time-sensitive cases to avoid inconsistent decisions.
Route visitors based on service complexity so short transactions do not get blocked behind lengthy cases.
Review queue data weekly to confirm that prioritization rules reduce wait times without creating new bottlenecks.
Structured segmentation brings order to high-volume environments and keeps wait times controlled across service networks.
Step 7 – Communicate Expected Wait Times Clearly
Clear communication stabilizes both actual and perceived wait times across service networks. When visitors understand how long they will wait, they plan better and remain calmer, even during peak periods. Silence increases uncertainty. Accurate updates reduce escalation.
To implement this effectively:
Display current wait times on in-branch screens and waiting room TVs so visitors can see queue movement in real time.
Send SMS updates with estimated wait time and position in line to reduce crowding near service counters.
Update estimates dynamically as demand changes to prevent misinformation.
Train staff to reference the same wait time data when answering visitor questions.
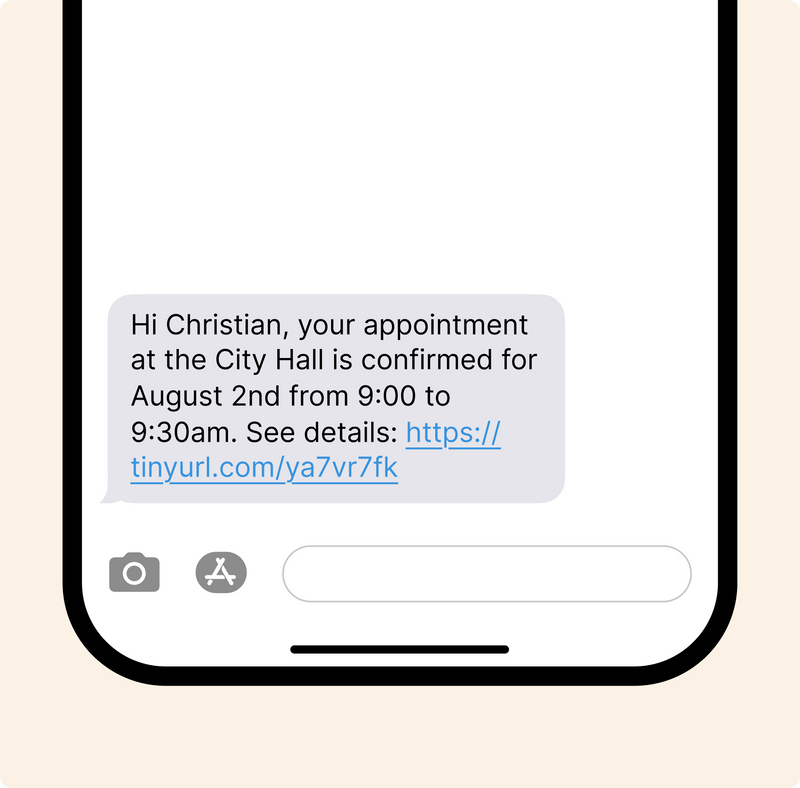
Transparent communication improves predictability and prevents frustration from spreading during longer wait times.
Read more - How to Improve Customer Communication With SMS Text Messaging
Control Wait Times with Qminder
Build Predictable Wait Times with Structure, Data, and Control
Predictable wait times do not happen by chance. Service networks must measure demand accurately, standardize workflows, align staffing with volume, and monitor performance in real time. When leadership tracks the right metrics and enforces consistent processes, wait time variability decreases. Clear communication and intelligent prioritization further stabilize operations during peak periods.
If your service networks struggle with fluctuating wait times, it is time to introduce structure and real-time visibility. Platforms like Qminder help large service networks control queues, monitor performance, and maintain predictable wait times at scale.
Start building a system your customers can rely on.
Large service networks should define acceptable wait time targets based on service type, complexity, and customer expectations. Transaction-based services may require shorter thresholds, while advisory services can allow longer windows. The key is setting measurable targets tied to capacity and demand patterns.
Queue abandonment indicates that wait times exceed customer tolerance. Tracking abandonment rates helps organizations identify when delays are driving visitors away and signals when staffing, routing, or service capacity adjustments are required.
Service networks should review wait time performance monthly or quarterly, depending on volume. Regular reviews ensure that changes in demand, staffing levels, or service offerings do not gradually increase variability over time.
Get to know the author

Aleksandra Sõsun Product Marketing Lead at Qminder
Get to know our solutions
We will give you a short but great overview of how Qminder can improve your business and visitors experience.
Try out Qminder for yourself and see how we can improve your business and visitors experience.



